2022. 11. 5. 17:09ㆍ개발 지식
🧐들어가며
JPA는 기본적으로 많은 메서드를 지원합니다.
특히 Spring의 Spring Data JPA는 Spring Data Repo가 사용하는 여러 리포지토리 메서드를 상속받고 있기 때문에
많은 메서드를 사용할 수 있습니다.

Spring Data Repo는 이렇게 기본적으로 리포지토리 리포지토리를 상속하고 있습니다.
특히 JPA는 기본 메서드뿐만 아니라 @Query 메서드를 사용해서 JPQL을 명시하여 사용할 수 있습니다.
🧐existsById
JPA에서 기본으로 제공하는 existsById는 어떤 방식으로 동작할까요?
Intellij에서 제공하는 JPABuddy를 사용하면 메서드의 쿼리를 추출할 수 있는 기능이 있습니다.

그러면 위와 같은 쿼리가 추출된다.
그런데 뭔가 이상합니다.
존재를 확인만 하면 되는데, 왜 카운팅을 하는 걸까요?
주로 MySQL 쿼리를 날려 존재 여부를 확인할 때는 다음과 같은 쿼리를 날려서 확인합니다.
select exists (select 1 from table where id = ?);
하지만 JPQL에서는 select 절의 exists를 지원하지 않습니다.(ANSI 표준 문법이 아니기 때문에)
그래서 select exists 대신 이렇게 count 방식을 사용하는 것입니다.
물론 대체제가 있긴 합니다.
findById를 사용하는 것이다.
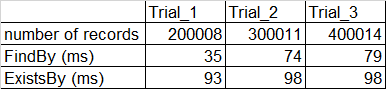
하지만 보시다시피 레코드가 많아지면 많아질수록 둘 간의 차이가 없어지는 것을 알 수 있습니다.
그럼 이를 어떻게 하면 최적화를 할 수 있을까요?
최적화에는 몇 가지 방법이 있습니다.
1. QueryDSL
exists가 count보다 성능이 좋은 이유는 전체 조회를 하지 않고 첫 번째 결과만 확인하기 때문입니다.
그렇기 때문에 limit을 이용해서 1개의 레코드만 조회하는 방식으로 최적화할 수 있습니다.
public boolean existsById(Long id) {
Integer result = jpaQueryFactory.selectOne()
.from(user)
.where(user.id.eq(id))
.fetchFirst();
return result != null;
}
이 메서드를 쿼리로 나타내면
select 1 from user u where u.id = :id limit 1;
이렇게 나타낼 수 있습니다.
(JPQL에서는 limit을 부분적으로 지원하지만 위와 같은 방식의 boolean 리턴으로는 지원하지 않는다.)
실제로 결과 역시 유의미하게 차이가 나는데,

시간이 61ms 에서 28ms로 최적화된 것을 확인할 수 있습니다.
2. Native 쿼리 사용하기
두 번째 방법으로는 JPA의 Native쿼리를 사용하는 방법이 있습니다.
JPA는 쿼리문을 Native쿼리에 맞게 번역해서 사용할 수 있는 기능이 있습니다.
이 기능을 이용하면 select exists를 사용할 수 있는데요, 아래와 같은 방법을 사용하면 됩니다.
@Query(value = """
select
case when exists(
select 1
from Product p
where p.name = :name
)
then 'true'
else 'false'
end
""",
nativeQuery = true
)
boolean existsByName(@Param("name") String name);
이런 쿼리를 사용하게 되면 네이티브 쿼리에 맞게 번역이 되어서 쿼리가 발생하게 됩니다.
단점이라면 매번 메서드와 쿼리를 둘 다 작성해야 한다는 불편함이 있습니다.
3. count로 최적화
마지막으로는 count로도 최적화가 가능합니다.
@Query(value = """
select count(p.id) = 1
from Product p
where p.name = :name
"""
)
boolean existsByName(@Param("name") String name);
하지만 이 방법의 경우 문제가 있습니다.
이 쿼리의 경우 반드시 UNIQUE한 값을 가지고 있을 때만 정삭적으로 작동합니다.
위의 경우 name이 반드시 UNIQUE해야한다는 것이죠.
고유한 값의 존재 여부를 확인할 경우에는 사용이 가능한 방법입니다.
나가며
지금까지 여러 최적화 방법을 알아봤습니다.
하나의 쿼리만 사용하면 될 경우, native 쿼리를 사용하는 방법이 편하고 좋을 수 있습니다.
확장성이나 코드의 가독성 등을 고려해서 사용한다면 QueryDSL이 좋은 대안이 될 수 있을 것입니다.
'개발 지식' 카테고리의 다른 글
| (Java 8) 자바 8에 추가된 함수형 인터페이스(Function, Predicate 등) (2) | 2022.11.20 |
|---|---|
| (Docker) Docker의 기본 명령어 모음(생성, 삭제..) (0) | 2022.11.07 |
| (운영체제) API? ABI? 리눅스 시스템 프로그래밍 (0) | 2022.10.25 |
| (Spring) DI/의존 객체 주입 패턴 + Lombok (0) | 2022.09.20 |
| (Git) Git의 저장구조(커밋 저장 구조) (0) | 2022.09.07 |